
I m Rahmen des Symposiums „Teachers as versatile communicators: Researching teacher-parent, teacher-student, and teacher-teacher verbal interaction“ stellten Monika Waldis und ich Ergebnisse aus unserem laufenden Projekt „Fachspezifisches Coaching in Lehrpraktika“ vor. Was mich vor allem interessierte war, ob die Einschätzungen der Lehrerstudierenden bezüglich der Ausprägung der Unterstützung durch ihre Praxislehrpersonen in der gemeinsamen Planung von Unterricht während Unterrichtsvorbesprechungen, mit den in den Videoaufnahmen analysierbaren Gesprächssequenzen übereinstimmte. Ob also diejenigen Gespräche, welche von den Lehrerstudierenden hohe Werte hinsichtlich der gemeinsamen, ko-konstruktiven Planung von Unterricht erhielten, auch tatsächlich mehr ko-konstruktive Sequenzen enthielten.
m Rahmen des Symposiums „Teachers as versatile communicators: Researching teacher-parent, teacher-student, and teacher-teacher verbal interaction“ stellten Monika Waldis und ich Ergebnisse aus unserem laufenden Projekt „Fachspezifisches Coaching in Lehrpraktika“ vor. Was mich vor allem interessierte war, ob die Einschätzungen der Lehrerstudierenden bezüglich der Ausprägung der Unterstützung durch ihre Praxislehrpersonen in der gemeinsamen Planung von Unterricht während Unterrichtsvorbesprechungen, mit den in den Videoaufnahmen analysierbaren Gesprächssequenzen übereinstimmte. Ob also diejenigen Gespräche, welche von den Lehrerstudierenden hohe Werte hinsichtlich der gemeinsamen, ko-konstruktiven Planung von Unterricht erhielten, auch tatsächlich mehr ko-konstruktive Sequenzen enthielten.
Ein Beispiel für eine als ko-konstruktiv kodierte Sequenz ist die nachfolgende (MT= Mentor Teacher; ST= Student Teacher):
MT: We can also count on various things being mentioned that maybe arent really. What are you going to do with those?
ST: Write them down as well. (–)
MT: And afterwards, at the blackboard (–)
ST: Yes, because =
MT: = arranging =
ST: = its actually a good idea of yours that I collect them because later when we get to the criteria and then write the entry into the theory notebook “ I think I may need less time depending and I also have to think of something, what will happen when I finish earlier “ but then we could surely (–) if we did it like this, so (-) and then “ that would actually be a cool ending “ we could go back to the start and see if all the things they said were rectangles, are they now really rectangles? And then we could quickly go through them together, yeah.
Tatsächlich konnten wir – bei den bisher analysierten Gesprächen – mehrheitlich eine Übereinstimmung finden. Die Einschätzungen der Studierenden stimmen mit unseren Kodierungen überein. Kodiert haben wir „ko-konstruktive“ Sequenzn (vgl. oben) in Anlehnung an Chi, M. (1996). Constructing self-explanations and scaffolded explanations in tutoring. Applied Cognitive Psychology, 10, 1-17. In diesem Artikel findet sich die folgende Definition: “ […] co-construction is generally viewed as having two (or more) people collaboratively construct a solution, an understanding, a shared meaning of knowledge, which neither partner possesses […] (Chi, 1996, p.5). Die Bestimmung, wann ein Dialog ko-konstruktiven Charakter hat, lehnt sich ebenfalls an Micheline Chi an: Chi, M. T. H., Siler, S. A., Jeong, H., Yamauchi, T. & Hausmann, R. G. (2001). Learning from human tutoring. Cognitive Science, 24(4), 471-533.
Vor allem die nachfolgende Abbildung ist leitend:
Zum Weiterlesen auf den Button klicken.

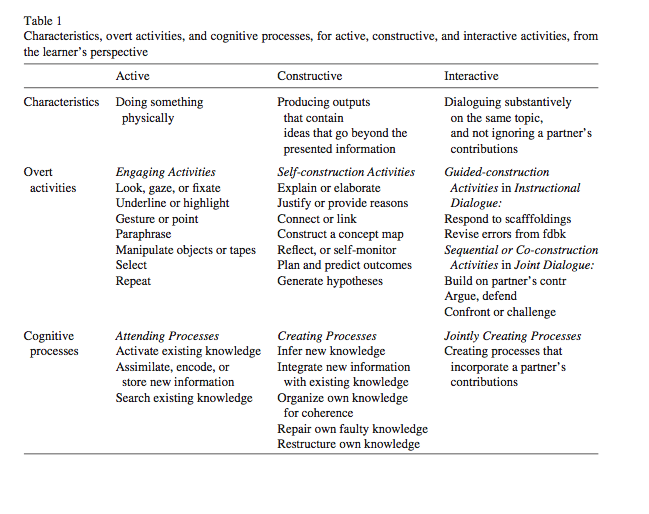
Ko-Konstruktive Dialoge sind solche, welche sowohl konstruktive als auch interaktive Anteile enthalten. Interaktiv im Sinne der Interaktion sind sie dann, wenn die Folgestruktur des Gesprächs mindestens dreischrittig ist. A fragt etwas, B reagiert darauf und A ergänzt/erwidert/etc. Falls lediglich eine kurze Bestätigung erfolgt von B und A dann mit etwas Neuem weiterfährt, ist dies keine Interaktion. Falls gemeinsam nichts „Neues“ generiert wird, keine (Ko-)Konstruktion. In einem 2009 erschienenen Paper: Chi, M. T. H. (2009). Active-Constructive-Interactive: A Conceptual Framework for Differentiating Learning Activities. Topics in Cognitive Science, 1(1), 73-105; zeigt Chi in einem Framework nochmals genauer die Unterscheidungen (vgl. Abbildung, zu finden im Text auf Seite 77).
Sehr spannend für mich war dann, dass am letzten EARLI-Tag ein Symposium zum Thema „Interactive instruction: Why it is effective and how it may be improved“ stattfand. Micheline Chi referierte als erste zum Thema: Using tutorial dialogues as instructional materials for students to observe.
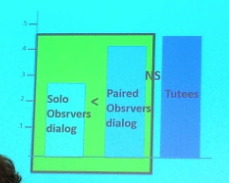 Die Anlage war, dass ein Tutor-Tutee-Problemlösedialog auf Video aufgezeichnet wurde und die Hypothese, dass Observer-Paare genauso viel lernen wie der/die Tutee im Video und mehr als eine einzelne Person, welche das Video betrachtet.
Die Anlage war, dass ein Tutor-Tutee-Problemlösedialog auf Video aufgezeichnet wurde und die Hypothese, dass Observer-Paare genauso viel lernen wie der/die Tutee im Video und mehr als eine einzelne Person, welche das Video betrachtet.
Dies weil: … if interactive and constructive are the basis of Tutees‘ learning advantage, then presumably, Paired Observers should learn as well as the Tutees.
In einer zweiten Studie wurde dieselbe Anlage wiederholt, diesmal waren es jedoch keine Dialoge, welche auf Video waren, sondern Monologe von denselben fünf Tutoren, welche ein Referat zu demselben Thema hielten. Hier schnitten die Dialog-Videos besser beim Lernzuwachs der beobachtenden Paare ab, als der Monolog. Die Hypothese ist, dass die Dialoge bei den „paired observer“ durch die Dialoge im Video stärker angeregt werden und dadurch interaktiver und konstruktiver sind, woraus mehr „Lernen“ abgeleitet werden kann. Spannend, nicht?